2024
Empowering Sign Language Communication: Integrating Sentiment and Semantics for Facial Expression Synthesis
Rafael Azevedo, Thiago M. Coutinho, João P. M. Ferreira, Thiago L. Gomes, Erickson R. Nascimento
Computer & Graphics 2024 en
Translating written sentences from oral languages to a sequence of manual and non-manual gestures plays a crucial role in building a more inclusive society for deaf and hard-of-hearing people. Facial expressions (non-manual), in particular, are responsible for encoding the grammar of the sentence to be spoken, applying punctuation, pronouns, or emphasizing signs. These non-manual gestures are closely related to the semantics of the sentence being spoken and also to the utterance of the speaker’s emotions. However, most Sign Language Production (SLP) approaches are centered on synthesizing manual gestures and do not focus on modeling the speaker’s expression. This paper introduces a new method focused in synthesizing facial expressions for sign language. Our goal is to improve sign language production by integrating sentiment information in facial expression generation. The approach leverages a sentence’s sentiment and semantic features to sample from a meaningful representation space, integrating the bias of the non-manual components into the sign language production process. To evaluate our method, we extend the Frechet gesture distance (FGD) and propose a new metric called Frechet Expression Dis- ´ tance (FED) and apply an extensive set of metrics to assess the quality of specific regions of the face. The experimental results showed that our method achieved state of the art, being superior to the competitors on How2Sign and PHOENIX14T datasets. Moreover, our architecture is based on a carefully designed graph pyramid that makes it simpler, easier to train, and capable of leveraging emotions to produce facial expressions. Our code and pretrained models will be available at: https://github.com/verlab/empowering-sign-language.
2021
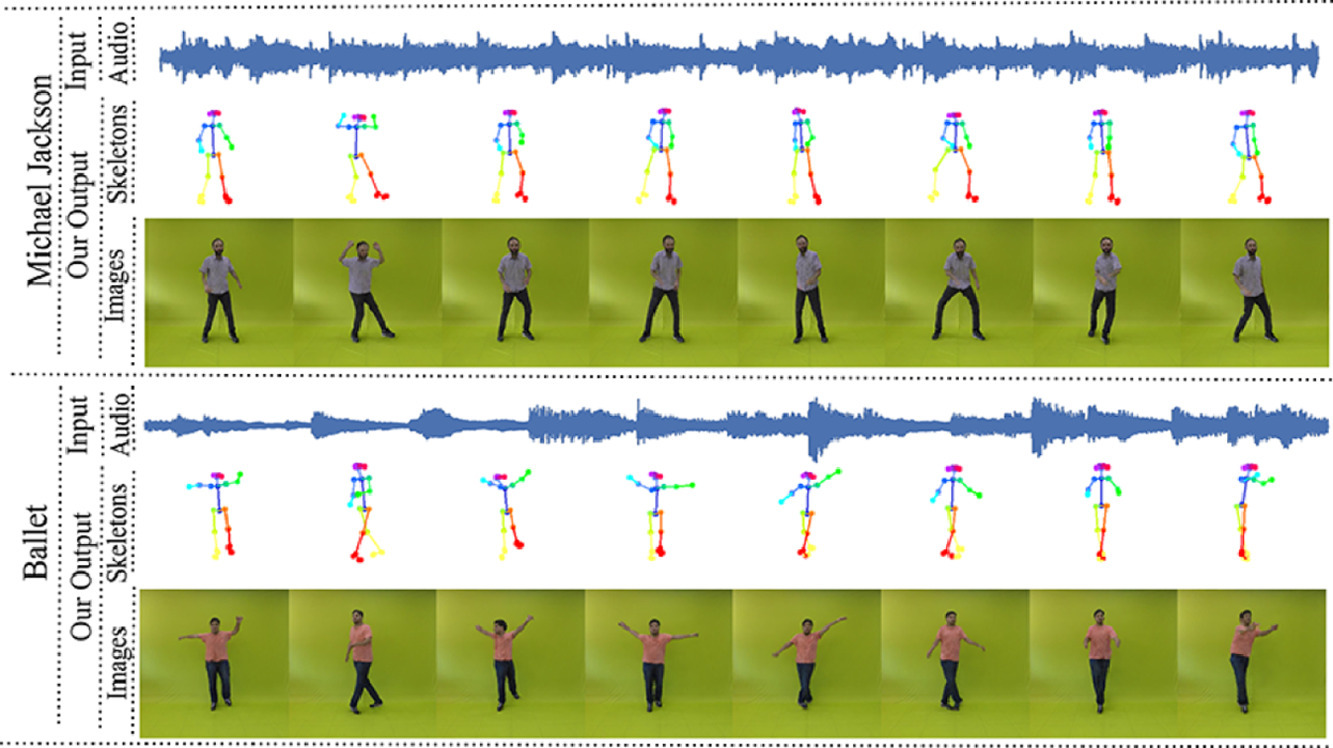
Synthesizing Realistic Human Dance Motions Conditioned by Musical Data using Graph Convolutional Networks.
João P. M. Ferreira, Renato Martins, Erickson R. Nascimento
Dissertation | SIBIGRAPI | CSBC 2021 en Best M.Sc. Dissertation SIBIGRAPI Finalist Best M.Sc. Thesis in Brazilian
Computing Society`s Contest
Synthesizing human motion through learning techniques is becoming an increasingly popular approach to alleviating the requirement of new data capture to produce animations. Learning to move naturally from music, i.e., to dance, is one of the more complex motions humans often perform effortlessly. Each dance movement is unique, yet such movements maintain the core characteristics of the dance style. Most approaches addressing this problem with classical convolutional and recursive neural models undergo training and variability issues due to the non-Euclidean geometry of the motion manifold structure. In this thesis, we design a novel method based on graph convolutional networks to tackle the problem of automatic dance generation from audio information. Our method uses an adversarial learning scheme conditioned on the input music audios to create natural motions preserving the key movements of different music styles. We evaluate our method with three quantitative metrics of generative methods and a user study. The results suggest that the proposed GCN model outperforms the state-of-the-art dance generation method conditioned on music in different experiments. Moreover, our graph-convolutional approach is simpler, easier to be trained, and capable of generating more realistic motion styles regarding qualitative and different quantitative metrics. It also presented a visual movement perceptual quality comparable to real motion data.

A Shape-Aware Retargeting Approach to Transfer Human Motion and Appearance in Monocular Videos
Thiago L. Gomes, Renato Martins, João P. M. Ferreira, Rafael Azevedo, Guilherme Torres, Erickson R. Nascimento
IJCV 2021 en
Transferring human motion and appearance between videos of human actors remains one of the key challenges in Computer Vision. Despite the advances from recent image-to-image translation approaches, there are several transferring contexts where most end-to-end learning-based retargeting methods still perform poorly. Transferring human appearance from one actor to another is only ensured when a strict setup has been complied, which is generally built considering their training regime’s specificities. In this work, we propose a shape-aware approach based on a hybrid image-based rendering technique that exhibits competitive visual retargeting quality compared to state-of-the-art neural rendering approaches. The formulation leverages the user body shape into the retargeting while considering physical constraints of the motion in 3D and the 2D image domain. We also present a new video retargeting benchmark dataset composed of different videos with annotated human motions to evaluate the task of synthesizing people’s videos, which can be used as a common base to improve tracking the progress in the field. The dataset and its evaluation protocols are designed to evaluate retargeting methods in more general and challenging conditions. Our method is validated in several experiments, comprising publicly available videos of actors with different shapes, motion types, and camera setups. The dataset and retargeting code are publicly available to the community at: https://www.verlab.dcc.ufmg.br/retargeting-motion.
2020
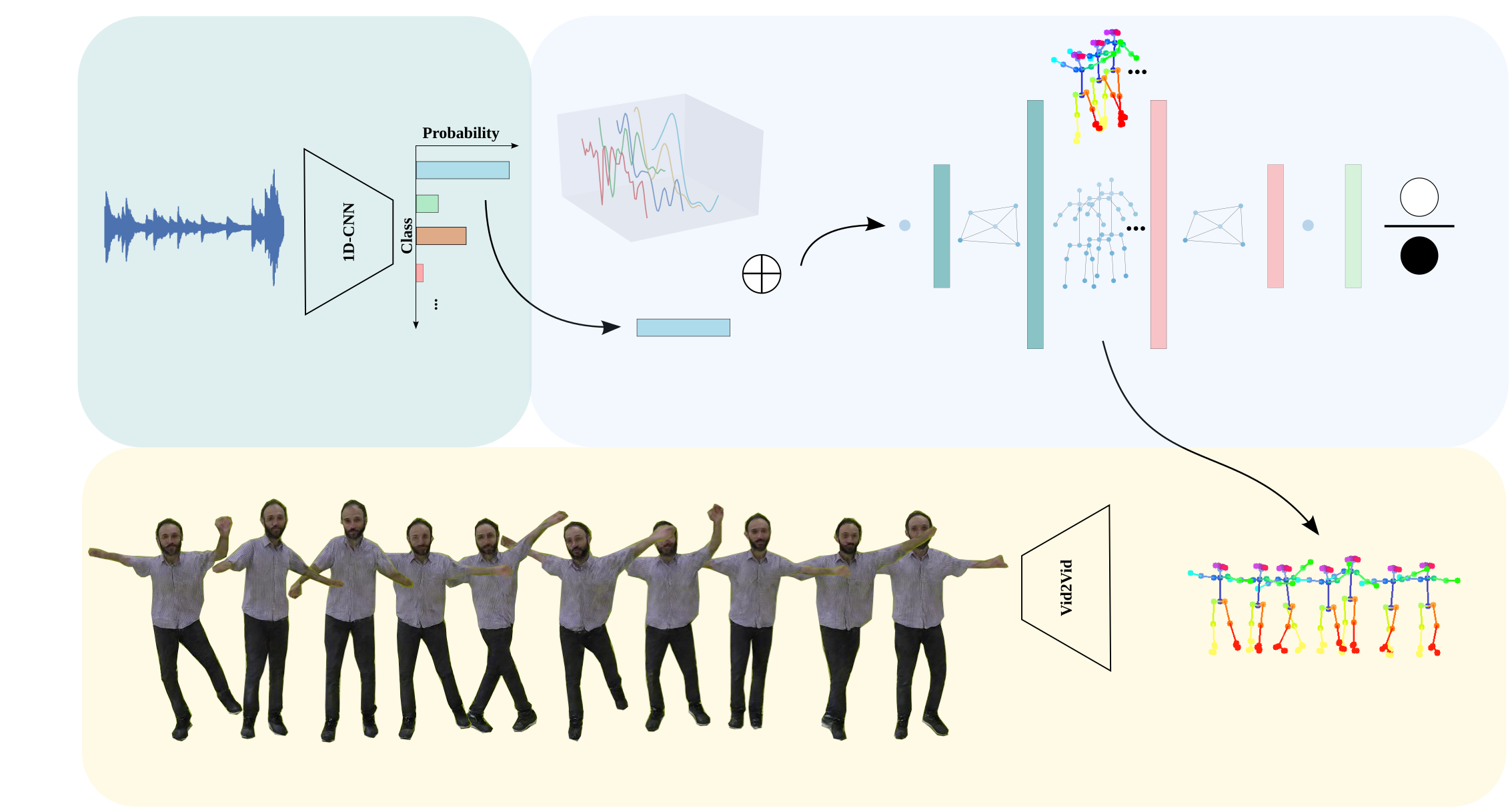
Learning to dance A graph convolutional adversarial network to generate realistic dance motions from audio
João P. M. Ferreira, Thiago M. Coutinho, Thiago L. Gomes, José F. Neto, Rafael Azevedo, Renato Martins, Erickson R. Nascimento
Computer & Graphics 2020 en
Synthesizing human motion through learning techniques is becoming an increasingly popular approach to alleviating the requirement of new data capture to produce animations. Learning to move naturally from music, i.e., to dance, is one of the more complex motions humans often perform effortlessly. Each dance movement is unique, yet such movements maintain the core characteristics of the dance style. Most approaches addressing this problem with classical convolutional and recursive neural models undergo training and variability issues due to the non-Euclidean geometry of the motion manifold structure. In this paper, we design a novel method based on graph convolutional networks to tackle the problem of automatic dance generation from audio information. Our method uses an adversarial learning scheme conditioned on the input music audios to create natural motions preserving the key movements of different music styles. We evaluate our method with three quantitative metrics of generative methods and a user study. The results suggest that the proposed GCN model outperforms the state-of-the-art dance generation method conditioned on music in different experiments. Moreover, our graph-convolutional approach is simpler, easier to be trained, and capable of generating more realistic motion styles regarding qualitative and different quantitative metrics. It also presented a visual movement perceptual quality comparable to real motion data. The dataset and project are publicly available at: https://www.verlab.dcc.ufmg.br/motion-analysis/cag2020.

Do As I Do Transferring Human Motion and Appearance between Monocular Videos with Spatial and Temporal Constraints
Thiago L. Gomes, Renato Martins, João P. M. Ferreira, Erickson R. Nascimento
WACV 2020 en
Creating plausible virtual actors from images of real actors remains one of the key challenges in computer vision and computer graphics. Marker-less human motion estimation and shape modeling from images in the wild bring this challenge to the fore. Although the recent advances on view synthesis and image-to-image translation, currently available formulations are limited to transfer solely style and do not take into account the character's motion and shape, which are by nature intermingled to produce plausible human forms. In this paper, we propose a unifying formulation for transferring appearance and retargeting human motion from monocular videos that regards all these aspects. Our method synthesizes new videos of people in a different context where they were initially recorded. Differently from recent appearance transferring methods, our approach takes into account body shape, appearance, and motion constraints. The evaluation is performed with several experiments using publicly available real videos containing hard conditions. Our method is able to transfer both human motion and appearance outperforming state-of-the-art methods, while preserving specific features of the motion that must be maintained (e.g., feet touching the floor, hands touching a particular object) and holding the best visual quality and appearance metrics such as Structural Similarity (SSIM) and Learned Perceptual Image Patch Similarity (LPIPS).

Connecting real world and "digital twins" with Multivisão system
Renato Forni, Mario F. M. Campos, Erickson Rangel do Nascimento, Luiz Chaimowicz, Douglas Guimarães Macharet, Milton Simas G Torres, Michel Melo da Silva, Tiago de Rezende Alves, João P. M. Ferreira, Daniel Balbino de Mesquita, Vitor Andrade Almeida de Souza, Guilherme Alvarenga Torres
Rio Oil & Gas Expo and Conference 2020 en Honorable Mention
The methodology of this work is two-fold, inspection and monitoring. For inspection, we use a robotic platform with a remote control. A web-based Human Machine Interface and an assisted built-in controller were developed to control the robotic platform in the industrial sites, aiming to prevent collisions, make the operation ease, and exhibit graphical elements to a better inspection. This system aims to assist the inspection of an industrial site in any of its lifecycle phases(construction, commissioning or operation) as well as to monitor its evolution through a remote view system and the reconstruction of a realistic three-dimensional virtual model. Regarding the evolutionary monitoring, we focus on the development and evaluation of algorithms and techniques for fusing data obtained by different sensors to perform the identification, tracking, reconstruction, and comparison with a 3D Model from Computer-Aided Engineering (CAE) in different scenarios. The novelty of the system is to provide an inspection tool transparent to the operator, regarding mechanical control and robotics expertise, that, at the same time, creates a safe interaction with the site workers. The use of augmented reality speeds-up the inspection effort. Additionally, the data fusion used to create 3D models and the automatic tool to compare the components already built with the 3D Model, CAE based, project facilitate the monitoring task. Another useful information prompted by the system is a graphical heat model depicting the difference between thecreated 3D model and the object's CAE.
2018
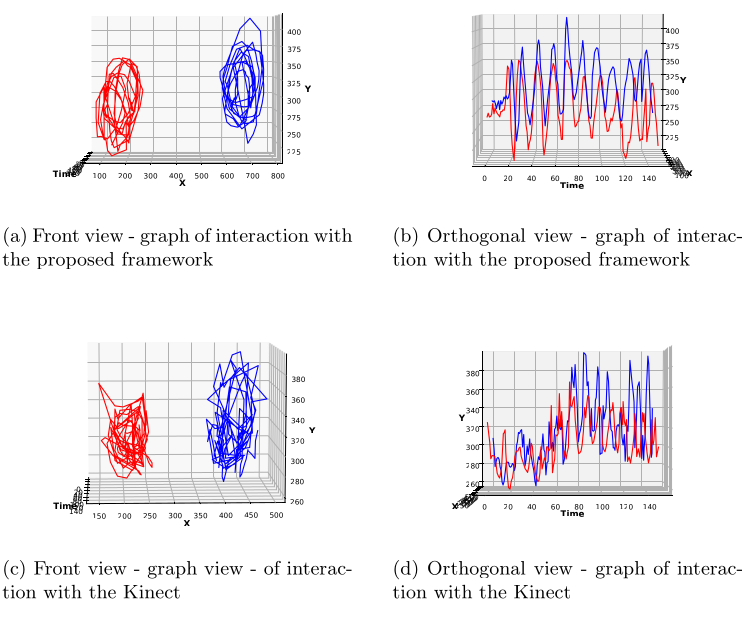
An RGB-Based Gesture Framework for Virtual Reality Environments
João P. M. Ferreira, Diego R. C. Dias, Marcelo P. Guimarães, Marcos A. M. Laia
ICCSA 2018 en
Virtual reality is growing as a new interface between human and machine, new technologies improving the development of virtual reality applications, and the user’s experience is extremely important for the science improvement. In order to define a new approach based on already established and easily acquired techniques of detection and tracking, an interaction framework was developed. The developed frame- work is able to understand basic commands through gestures performed by the user. Making use of a simple RGB camera. It is able to be used in a simple virtual reality application, allowing the user to interact with the virtual environment using natural user interface, focusing on presenting a way to interact with users without deep knowledge of computing, pro- viding an easy-to-use interface. The results shows to be promising, and the possibilities of its uses are growing.
Desenvolvimento de Instrumentos Musicais Digitais a partir de dispositivos ubíquos
Gabriel Lopes Rocha, Avner Maximiliano, João P. M. Ferreira, Flávio Luiz Schiavoni
VIII Workshop on Ubiquitous Music (UBIMUS) 2018 pt-br
This paper presents a study on the creation of digital musical instruments from ubiquitous devices. In this study, we applied the process for creating a digital musical instrument starting with the choice of a videogame control and a video camera as input devices. We present the outcome ot his implementation, the design decisions taken during this development and also the considerations on how the creative process can influence and be influenced by technological decisions
2017

Uma Abordagem para Detecção Gestos Voltada a Ambientes de Realidade Virtual e Aumentada
João P. M. Ferreira, Marcos Laia, Diego Roberto Colombo Dias
Symposium on Virtual and Augmented Reality - WIC 2017 pt-br Honorable Mention
New technologies for the detection and monitoring of body expressions are necessary for new ways of accessing computational elements, new modes of visualization and interaction in virtual environments. To dene a new approach based on already established and easily acquired techniques, a detection and tracking, system was developed to understand basic commands through gestures performed by the members of the user’s body. Detected by an image capture system made by a simple camera, a group of users is tracked, interacting with virtual environments that have manipulable objects. The initial system focuses on presenting a way to interact with users without deep knowledge of computing, providing an easy-to-use interface, where patterns and people generate input stimuli in a natural and intuitive way, aiming to interact with virtual objects contained in the system output.

The Framework of Copista: An OMR System for Historical Music Collection Recovery
Marcos Laia, Flávio Schiavoni, Daniel Madeira, Dárlinton Carvalho, João P. M. Ferreira, Júlio Resende, Rodrigo Ferreira
Lecture Notes in Computer Science. 1ed.: Springer International Publishing, 2017, p. 65-87 2017 en
Optical Music Recognition (OMR) is a process that employs computer science techniques to musical scores recognition. This paper presents the development framework of “Copista”, an OMR system proposed to recognize handwritten scores especially regarding a historical music collection. “Copista” is the Brazilian word for Scribe, someone who writes music scores. The proposed system is useful to music collection preservation and supporting further research and development of OMR systems.